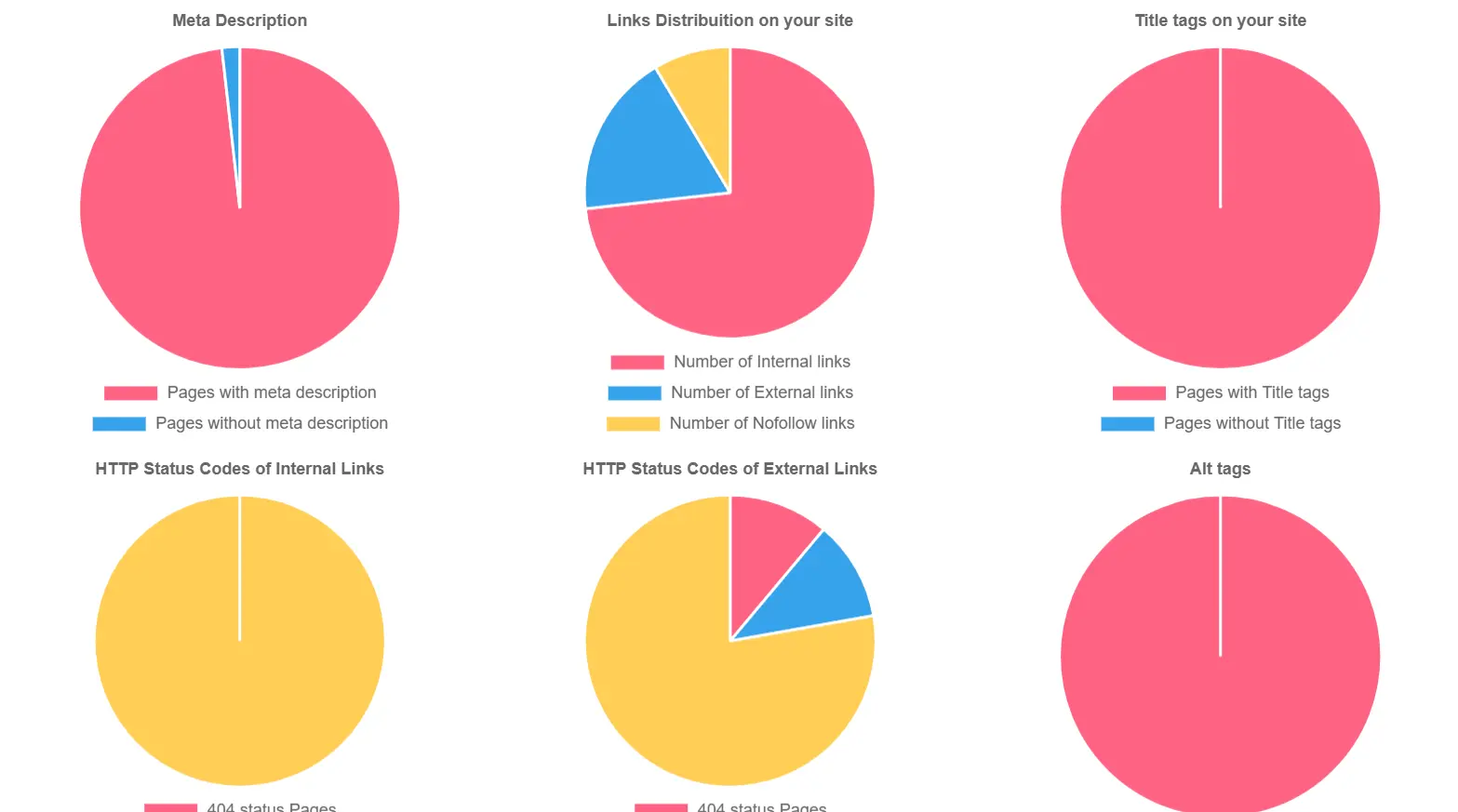
Visual results of analysis
Website Crawler displays the analysis in a pie chart, making it easy to find areas that need optimization. It generates a pie chart for loading times, internal/external links, HTTP status codes, content, etc. If you spot an issue, re-run a crawl and see the latest results. Our charts are updated in real-time. You can compare the current charts with the past ones by using our "crawl history" utility which shows a list of all crawl jobs you've executed and a timestamp.
Data extraction
With WebsiteCrawler, you can extract data from websites with just a click of a button. Once a crawl job is complete/over, your data is available for download instantly. You can download the data in a CSV, Markdown, or JSON format file. We also offer an API which supports data retrieval in JSON format in case you want structured data for your project/software. You can configure the "custom tag settings" to scrape information of your choice from web pages.
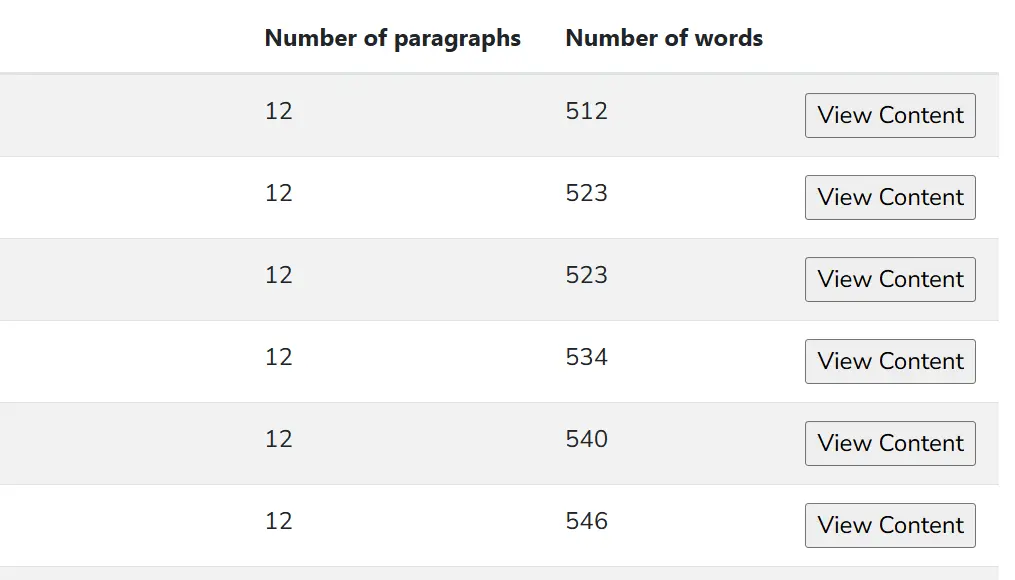
Technical reports
The visualization of data is just the first step in making your website better. We provide detailed reports of analysis so that you can fix the issues, improve the site's search presence and performance. We let users filter data with many conditions. From finding internal redirects to identifying dead/unused CSS/JavaScript code, and detecting pages with duplicate content, we provide many reports that will help you improve your site.
Intuitive settings
Configure the crawl behavior by selecting the crawler type, change the number of URLs to process per minute and introduce a delay. Track credit usage, and see crawl history. Add your branding to the PDF reports, and activate modes like "Markdown". Configure email alerts, blacklist/whitelist directives, and more all from one place.